The AI feature ships, usage grows, and then the bill arrives — and it's growing faster than revenue. This is the moment a lot of GenAI products quietly stall: the unit economics don't work because the team optimized for 'does it work' and never for 'what does each call cost.' The encouraging news is that most LLM bills are full of waste, and the biggest savings come without touching quality. You don't need a cheaper model so much as a smarter system around the model.
Tokens are the meter — and you're overpaying on input
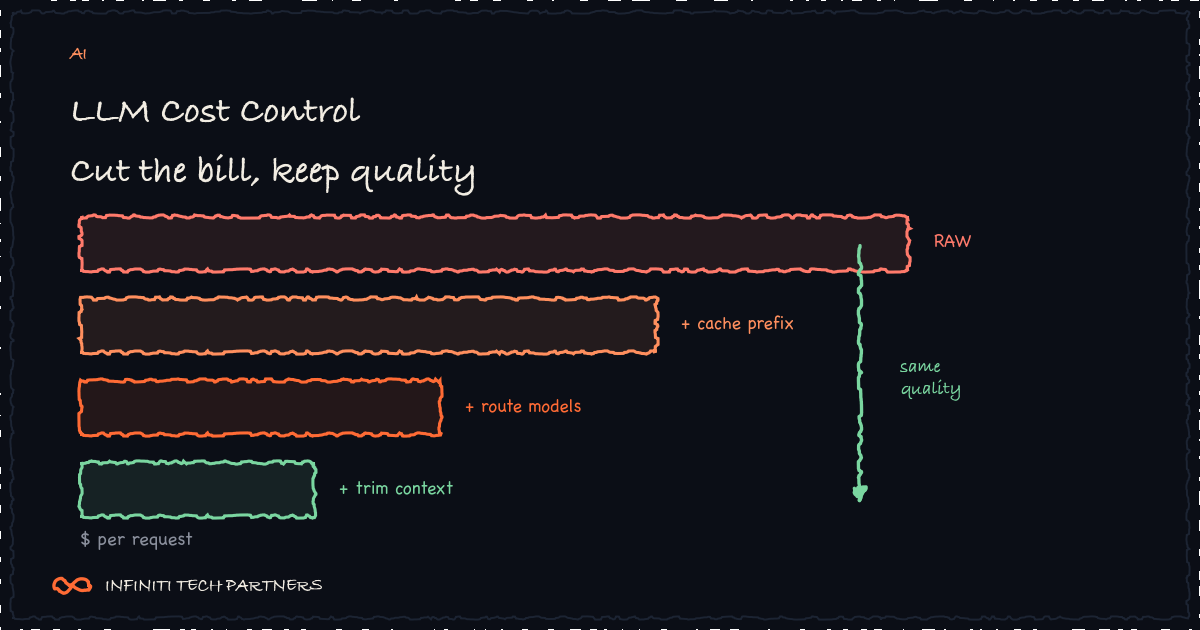
You pay per token, in and out, and the asymmetry surprises people: for most real applications the input dominates. Every call drags along a long system prompt, retrieved documents, and a growing conversation history, and you pay for all of it on every single turn. Teams obsess over the model's price-per-token and ignore that they're sending ten thousand tokens of context to answer a question that needed five hundred. The first place to look for savings is almost never the model — it's how much you're stuffing into each request.
Prompt caching: stop paying for the same prefix
If every request begins with the same large, static block — your system instructions, tool definitions, few-shot examples, a fixed knowledge base — prompt caching lets the provider charge a fraction of the price for that repeated prefix. The structural trick is ordering: put everything stable at the front of the prompt and everything variable (the user's actual message) at the end, so the cacheable prefix is as long as possible. For chat and agent workloads that replay a big system prompt thousands of times an hour, this one change can cut input costs dramatically with zero quality impact and almost no engineering.
Model routing: right-size each request
Not every request needs your most capable, most expensive model. A huge share of real traffic — classification, extraction, short factual answers, routing decisions — is handled perfectly by a smaller, cheaper, faster model. The pattern is a tiered cascade: send each request to the cheapest model that can do the job, and escalate to a bigger model only for the genuinely hard ones (or when a quick confidence check on the cheap model's answer says to). Done well, the user never notices, latency improves, and a large fraction of volume moves off your premium model. Routing is usually the single biggest lever after caching.
Context discipline and output limits
- Retrieve less, but better. Stuffing 20 documents into context 'to be safe' is expensive and often worsens answers; tighten retrieval to the few chunks that matter.
- Trim conversation history. Summarize or window long chats instead of replaying the entire transcript every turn.
- Cap output length. Open-ended generations drift long; set sensible max-output limits and ask for concise answers.
- Cache full responses for repeated identical questions — an FAQ-style hit shouldn't reach the model at all.
Measure per-feature, then set a budget
You can't control what you don't attribute. Tag every LLM call with the feature, the model, and the tenant, and put cost-per-request on a dashboard next to usage. Almost always a few features or a few heavy tenants drive the majority of spend — and once you can see that, the optimization work targets itself. Then set a token budget per feature as a guardrail, so a runaway loop or an abusive tenant trips an alert instead of a five-figure surprise at month-end. Cost observability is what turns one-off cleanups into spend that stays under control as you scale.
How Infiniti Tech Partners controls AI spend
We instrument your AI stack for per-feature cost visibility, then apply the levers in order of impact — prompt caching, model routing, retrieval and context discipline, output caps — so the bill drops without users noticing. The goal is GenAI features whose unit economics actually work at scale, not a demo that's quietly bleeding margin. If your AI costs are outrunning your revenue, start a conversation.
Related reading
Building a Private AI Assistant on Your Own Data: Architecture & Pitfalls
How to build a private, secure AI assistant grounded in your company's own data — the retrieval architecture, access control, and the pitfalls that sink most internal LLM projects.
AIAI Agents in Production: Lessons from 10 Enterprise Rollouts
What separates AI agent projects that reach production from the ones that stall in demo — evaluation, scope, guardrails, and human oversight, drawn from real enterprise rollouts.
AIRAG vs Fine-Tuning vs Agents: Choosing the Right LLM Pattern in 2026
How to choose between RAG, fine-tuning, and agents for an enterprise AI system — with a decision tree, cost benchmarks, and the mistakes that cost teams 3–6 months.