Most SaaS disaster recovery plans share one fatal trait: they have never been tested. There's a backup job, a wiki page, and a comforting assumption that if the worst happens, it'll all work out. Then a region goes down or someone drops a production table, and the team discovers the backups are corrupt, the restore takes nine hours, or nobody knows who has the access to run it. A real DR plan starts with two honest numbers — RTO and RPO — and then proves, on a schedule, that you can actually hit them.
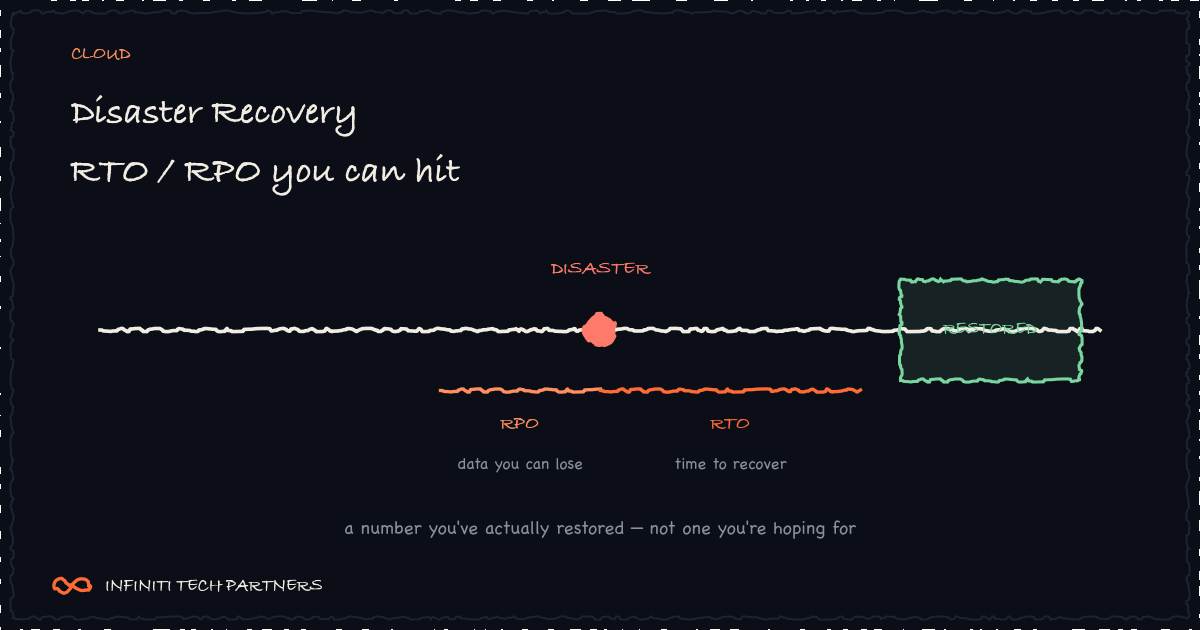
RTO and RPO: the two numbers that drive everything
Recovery Time Objective (RTO) is how long you can be down before it's unacceptable. Recovery Point Objective (RPO) is how much data you can afford to lose, measured in time. If your RPO is five minutes, you need replication or backups at least that frequent; if your RTO is one hour, a restore process that takes six is a failure no matter how good the backup is. These targets aren't an engineering preference — they're a business decision, and different data deserves different numbers. Your core transactional database might warrant minutes; a regenerable analytics cache might tolerate a day. Set them deliberately, write them down, and design backward from them.
Backups you haven't restored are not backups
The most dangerous phrase in operations is 'we have backups.' A backup is a hypothesis until you've restored it. Backups silently corrupt, exclude a critical volume, encrypt with a key nobody can find, or take far longer to restore than anyone estimated. The only way to know your RPO and RTO are real is to perform actual restores on a schedule — into a clean environment, timed, verified for data integrity. A quarterly restore drill that produces a working system and a stopwatch number is worth more than a year of green backup-job dashboards. Test the restore, not the backup.
High availability is not disaster recovery
Teams often conflate the two and end up protected against the wrong failure. High availability — multi-AZ databases, redundant instances, load balancers — keeps you running through routine hardware and instance failures, and you should have it. But HA replicates your current state, including mistakes: a bad migration, a malicious actor, or an accidental mass-delete propagates to every replica instantly. Disaster recovery is what saves you from those — point-in-time backups you can roll back to, copies in a separate region or account that a compromise of your primary can't reach. You need both, and you need to be clear about which threat each one actually addresses.
The runbook has to work at 3am
- Write the recovery procedure as a step-by-step runbook a stressed on-call engineer can follow — not tribal knowledge in one person's head.
- Ensure access works during the disaster: if recovery needs credentials that live only in the system that's down, you have a deadlock. Keep break-glass access out-of-band.
- Define who decides to invoke DR, and how you communicate to customers and status page while it's underway.
- Store backups and the runbook in a blast radius separate from production — a different region or account — so the failure can't take out your recovery path too.
Practice the disaster before it practices on you
The teams that recover calmly are the ones who've rehearsed. Run a game day: deliberately fail over to your secondary, or restore production into a fresh environment, with the people who'd actually be on call, using only the runbook. You'll find the gaps — a missing permission, a step that's out of date, an RTO that's twice your target — while it's a drill and not an outage. Then fix them and do it again. DR is not a document you write once; it's a capability you maintain, and the only proof it works is that you've recently watched it work.
How Infiniti Tech Partners builds resilience
We set RTO and RPO targets against your real business risk, build the backup, replication, and cross-region recovery to meet them, and then prove it with scheduled restore drills and game days — plus a runbook your on-call can actually execute under pressure. Resilience you've tested, not resilience you're hoping for. If your DR plan has never survived a real rehearsal, start a conversation.
Related reading
Edge Computing for SaaS: When the Latency Is Worth the Complexity
Edge computing promises lower latency and resilience, but adds real operational cost. A pragmatic 2026 guide for SaaS CTOs on when the edge pays off — and when a good CDN is enough.
CloudKubernetes or Serverless? The 2026 Decision Tree for Growth-Stage CTOs
When to run Kubernetes, when serverless cuts cost, and how most growth-stage companies use both — with a four-factor decision framework and cost benchmarks.
CloudAWS Cost Optimization: 12 Levers for SaaS at $5M–$50M ARR
The 12 levers that cut a growth-stage SaaS company's AWS bill by 30–50% — from rightsizing and savings plans to data-transfer and architecture fixes — without slowing the team down.