The 2am maintenance window is a confession that you can't change your database safely while it's running. For a modern SaaS with customers in every timezone, there is no 2am — someone is always working. The good news is that almost every schema change can be shipped to a live database with zero downtime, if you stop thinking of a migration as a single atomic event and start thinking of it as a sequence of individually-safe steps — the same incremental, reversible philosophy behind a monolith-to-microservices migration. The pattern that makes this work has a name: expand and contract.
Why the naive migration breaks
The instinct is to bundle the schema change and the code change into one deploy: rename the column, ship the new code that uses it, done. But your application doesn't switch over instantly — during a rolling deploy, old and new code run side by side for minutes. The old code queries a column that no longer exists; the new code queries one the old schema doesn't have. Either way, requests fail. Worse, some operations take a lock: adding a NOT NULL column with a default, or an index without the CONCURRENTLY option, can lock the table long enough to stall every query behind it. The fix is to never require old and new to agree at the same instant.
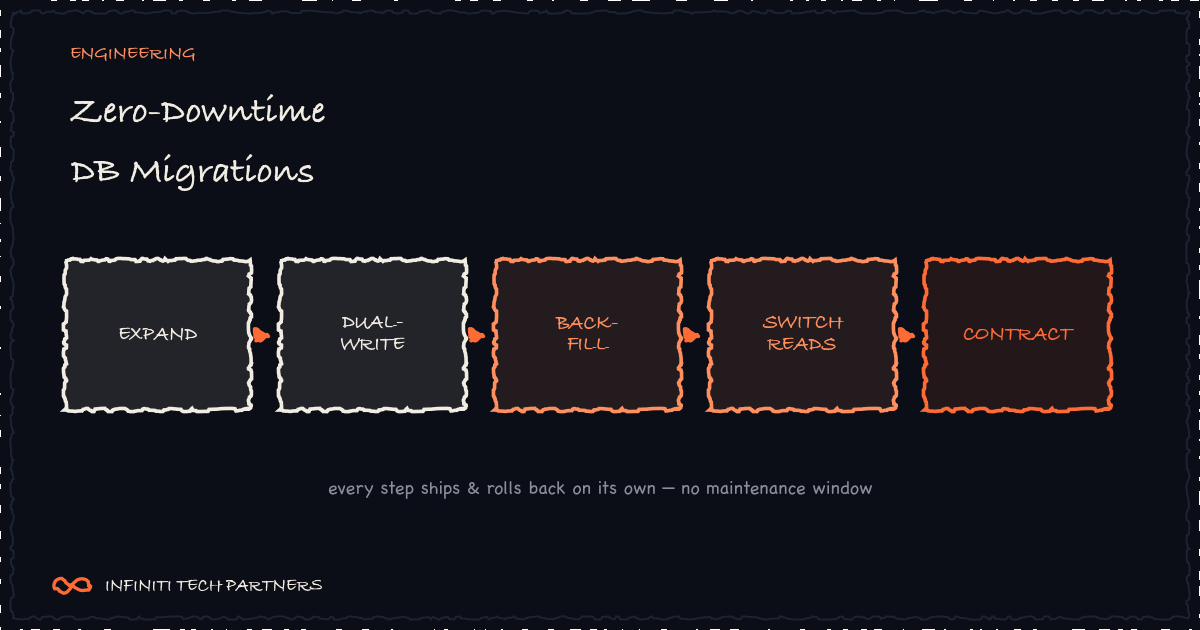
Expand and contract, step by step
- Expand: make an additive, backward-compatible schema change. Add the new column or table; never drop or rename in this step. Old code keeps working untouched.
- Dual-write: deploy code that writes to both the old and the new shape, while still reading from the old. Now both representations stay in sync going forward.
- Backfill: copy historical data into the new shape in small batches, so the new column is fully populated without a single long-running, lock-holding UPDATE.
- Switch reads: once the new column is verified complete and consistent, deploy code that reads from it. The old column is now write-only dead weight.
- Contract: after a safe bake-in period with no rollbacks pending, stop writing the old column and drop it in a final, separate migration.
The rename that taught everyone this
Renaming a column is the canonical example because the naive version is guaranteed to break. You can't 'rename user_name to full_name' on a live system — there is always a moment when one half of your fleet expects each name. Instead you add full_name (expand), write both (dual-write), copy user_name into full_name (backfill), move reads to full_name (switch), and finally drop user_name (contract). Five boring, reversible steps replace one risky one. Every step is independently deployable and independently revertible, which is the whole point: at no moment is the system in a state it can't recover from.
Locks, indexes, and the gotchas that bite
Even additive changes can hurt if you ignore locking behavior. On Postgres, build indexes with CREATE INDEX CONCURRENTLY so you don't block writes. Add a column without a volatile default on hot tables, then backfill, rather than forcing a full table rewrite. Set a short lock_timeout so a migration that can't acquire its lock fails fast instead of queuing every transaction behind it. Backfill in bounded batches with a pause between them so you don't saturate I/O or replication. And add the NOT NULL constraint as NOT VALID first, then VALIDATE separately — validation scans without holding the heavy lock.
Make it the default, not the heroics
Zero-downtime migration shouldn't be a special project; it should be how every migration is written. That means a migration tool that runs changes in the right order, a CI check that flags dangerous operations (a bare rename, a non-concurrent index, a blocking default) before they merge, and a team habit of splitting one logical change across multiple deploys. The discipline feels slower for a week and then disappears into muscle memory — and you never schedule a maintenance window again.
How Infiniti Tech Partners ships schema changes
We set up the migration tooling, CI guardrails, and expand-and-contract workflow that let your team evolve the database continuously without downtime or 2am windows — including the backfill and dual-write plumbing for the genuinely hard changes. If your deploys still depend on a quiet hour that no longer exists, let's fix the foundation. Start a conversation.
Related reading
Monolith to Microservices Without Freezing the Roadmap
How to migrate a monolith to microservices incrementally — using the strangler pattern — without a risky big-bang rewrite or a multi-quarter feature freeze that stalls the business.
EngineeringWhat "Production-Ready" Actually Means (and Why Most MVPs Aren't)
A concrete definition of production-ready software — the checklist a growth-stage team should clear before calling an MVP done, and where most fall short.
EngineeringThe 2026 Build vs Buy Decision Framework for Growth-Stage CTOs
A practical framework for deciding when to build custom software, when to buy off-the-shelf, and when to do both — with the hidden costs most teams miss on each side.